Low latency networking between AWS regions
Finding an 8 millisecond improvement between AWS Tokyo and Singapore by exploring undocumented AWS internals

When every millisecond matters
The latency of routes between AWS Tokyo and Singapore are of critical importance in the world of low latency crypto trading. While nowhere near as competitive as more established markets in TradFi, a 2-3ms improvement on this route would represent a material advantage. But by no means is this post focused on crypto. This is the last time you’ll see me mentioning it in this post.
Bigger players have already moved onto low latency fiber, and exploring microwave - but there’s still a way one could get close to the optimal latency, without paying for all this expensive infrastructure - and it relies on a little bit of gaming of AWS infrastructure.
To date, AWS has been fairly tight-lipped about their infrastructure setup. AWS would love to have you treat all their hardware as being totally “fungible”, and all their underlying network setup opaque - but in this post, we’re going to explore a little bit about the how and why AWS has interconnected their Tokyo and Singapore regions. Please note though, I’ve never worked at AWS - but I do have a passive interest in networking - so all I can do is make educated guesses.
First looks - what does the route look like?
If you simply ping an IP in AWS Tokyo from AWS Singapore, you’d get bored fairly quickly. You’d probably see a little bit of jitter, but not a lot. Boring! However, if you left the ping running for over an hour, you might notice a regime change in the latency. Once every 30 to 45 minutes, the “mean” latency between the routes is changing! What could be causing this behavior?
Regime changes in latency
You might run a traceroute between the two locations, hoping to catch wind of a route change. Route changes usually manifest themselves as a change in the number of intermediate hops, as well as the “names” (RDNS) of the intermediate hops. But even running MTR across a latency regime change doesn’t result in a visible change in the route - only latency! What could be going on here?
We have to dig deeper for the answer. Literally. When network engineers are talking about route changes, they’re usually talking about Layer 3 route changes in the OSI model. But as mentioned before, AWS seemingly tries to make this as opaque as possible to you. The Layer 3 route is not changing - but the Layer 2 route is! Enter MPLS (Multi Protocol Label Switching).
The role of MPLS in joining long-haul routes
MPLS has two features that make it interesting. First, it can make multiple “hops” appear as a single route. This is useful for long-haul links because it simplifies the problem space when making routing decisions. Secondly, it’s capable of performing load balancing across a basket of underlying routes.
Translation? MPLS can make multiple diverse fiber paths (with varying lengths, and therefore, latency) appear as a single path. This would mean that this underlying infrastructure is not visible to tools like traceroute - but its effects are visible in the form of regime changes in latency across a connection.
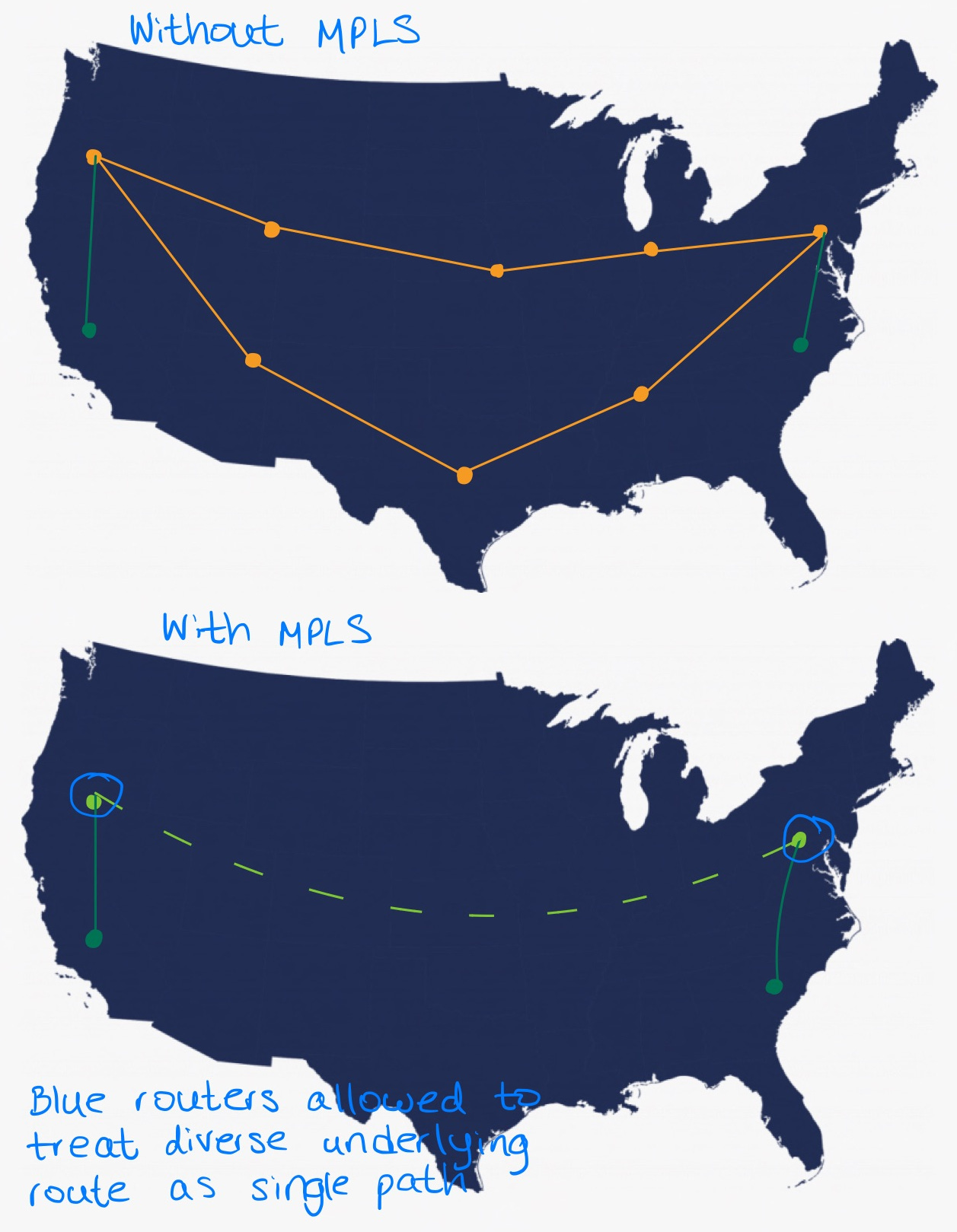
Note how with MPLS, intermediate hops no longer have to perform routing decisions - the blue routers make the decision once, and every intermediate underlying router simply passes it along the preconfigured path
Load balancing (and rebalancing) with MPLS
I’m no expert in MPLS, but load balancing at a packet level (rather than Layer 7 load balancing, for example with HTTP) has certain constraints - and those constraints are solved the same way over and over again, because they make sense.
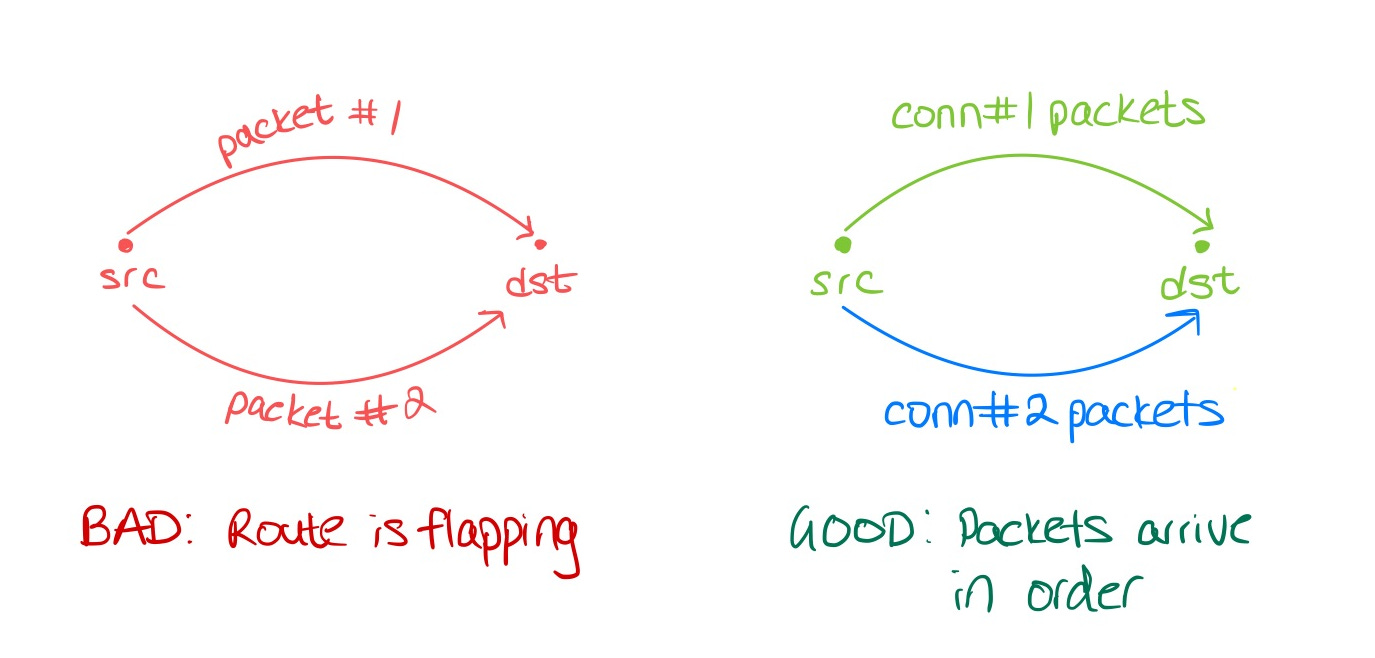
The elephant in the room: Route flaps must be avoided. For a given connection, if every first packet goes down route 1, and every second packet goes down route 2, the smallest variation in latency between route 1 and 2 would result in packets arriving out of order on the receiving end. This has critical performance implications for things like TCP - when packets start to arrive out of order, TCP thinks the link is getting close to saturated, or packets are getting dropped - and it signals to the transmitting end “Hey! Slow down over there!” This means that any load balancing solution must ensure that traffic for the same connection, always goes down the same physical path, regardless of what clever tricks engineers have done to try to hide routes. If they don’t, the variation in latency will kill performance.
So how do you load balance traffic at a packet-level across multiple diverse underlying routes, without killing performance? The answer (as is the answer to all distributed system problems) - is hashing. The key lies in the fact that packets associated with the same connection must not be allowed to flap. There’s nothing that would prevent packets from two different connections, from taking two different routes - so long as each connection itself does not go back and forth.
In practice, the key for this hash will usually be something called the 5-tuple. That is, (protocol, src_ip, dst_ip, src_port, dst_port). The hashing algorithm itself must be bi-directional, which means that packet from src→dst and dst→src, which would normally manifest itself as different 5-tuples, should yield the same hash output. In practice, this is accomplished with XOR, but this is beyond the scope of this document. Protocols that don’t have ports (e.g. ICMP) will assume some sane default, such as 0, for the purposes of the hash.
But why the regime change? My guess here is that every 30-45 minutes (or triggered by some unknown underlying condition), AWS decides to rebalance the traffic between their routes. They could do this by changing some seed in the hash generation. Although I mentioned earlier that traffic for the same connection should never change routes, in practice, a few route changes here and there only cause momentary degradation in performance. For 99% of applications, this is no problem.
Gaming the system (or the TL;DR: for those that just want the how, and not the why)
Open up multiple connections. Because each connection will have a different 5-tuple, the more connections you open, the more likely it is your connections are dispersed among all the varying underlying paths that there may be.
You must constantly measure the latency of traffic across every connection - not just use a tool like ping (because remember, ICMP assumes a port of 0, so the 5-tuple would only have src and dst IP as controllable fields, always yielding the same hash key). That means implementing some kind of “ping” using your own protocol on top of TCP (or UDP, if you’re using UDP).
Now that you’re measuring the latency of every connection, it becomes a simple matter of choosing to send your traffic over only the fastest connection.
The empirical findings
To date, AWS seems to have 3 diverse paths connecting Tokyo and Singapore. Of those, the worst path is 8ms slower than the fastest path. The middle path is only 1-2ms slower than the fastest path. AWS seems to rebalance their traffic once every 30-45 minutes, which manifests itself as regime changes in latency for a given connection. Having worked with multiple low-latency fiber providers between this route specifically, I can say that it’s only a few milliseconds faster than the fastest AWS route :)
Closing thoughts
Low latency fiber is still going to be faster than AWS’s throughput-optimized links. But I hope I’ve illustrated that the gap between the two is not actually as bad as it seems. And of course, the findings in this post could hopefully be applied to other industries where latency is a problem - online multiplayer video games, for example. Lastly, the above findings could probably be reproduced on other routes between AWS facilities as well!
Very well thought out and explained in clear points.
This was an awesome and insightful read! Nice work reverse engineering this. Did you ever end up building some utility/application on top of this to always use the fastest connection?